HDFS / MongoDB Performance 관련
하둡의 native library 써보기
Sort
sequential file로 만들고, sequential file 형식을 받아서 sorting함(sequence file은 hdfs dfs -text
# sequence file 1GB짜리 두개 생성.
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar randomwriter -D mapreduce.randomwriter.bytespermap=1073741824 -D mapreduce.randomwriter.mapsperhost=1 /data/sort/in
# sorting
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar sort /data/sort/in /data/sort/out
# 텍스트로 가져오기(용량 크니까 tail 명령어 같은걸로 잘라서 보기)
hdfs dfs -text /data4/sort/out/* > result
# (추가) Format에 옵션을 줬을 때 돌아감. 형식은 어떻게 맞춰야 하는지 아직 모르겠다.
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar sort -inFormat org.apache.hadoop.mapreduce.lib.input.TextInputFormat -outFormat org.apache.hadoop.mapreduce.lib.output.TextOutputFormat -outKey org.apache.hadoop.io.LongWritable -outValue org.apache.hadoop.io.Text /tmpya /ho/
-> sequence file형식으로 만들고 output도 sequence file로 내기 때문에 mongodb에 자료를 넣기 어렵고 정확한 성능비교도 어려울 것 같다.
TestDFSIO
# https://github.com/apache/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/src/test/java/org/apache/hadoop/fs/TestDFSIO.java
hadoop jar /usr/local/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-*tests* TestDFSIO
# https://github.com/apache/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/src/test/java/org/apache/hadoop/fs/DFSCIOTest.java
hadoop jar /usr/local/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-*tests* DFSCIOTest
# tera sort 관련
hadoop jar /usr/local/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-*examples*.jar teragen
실행 결과
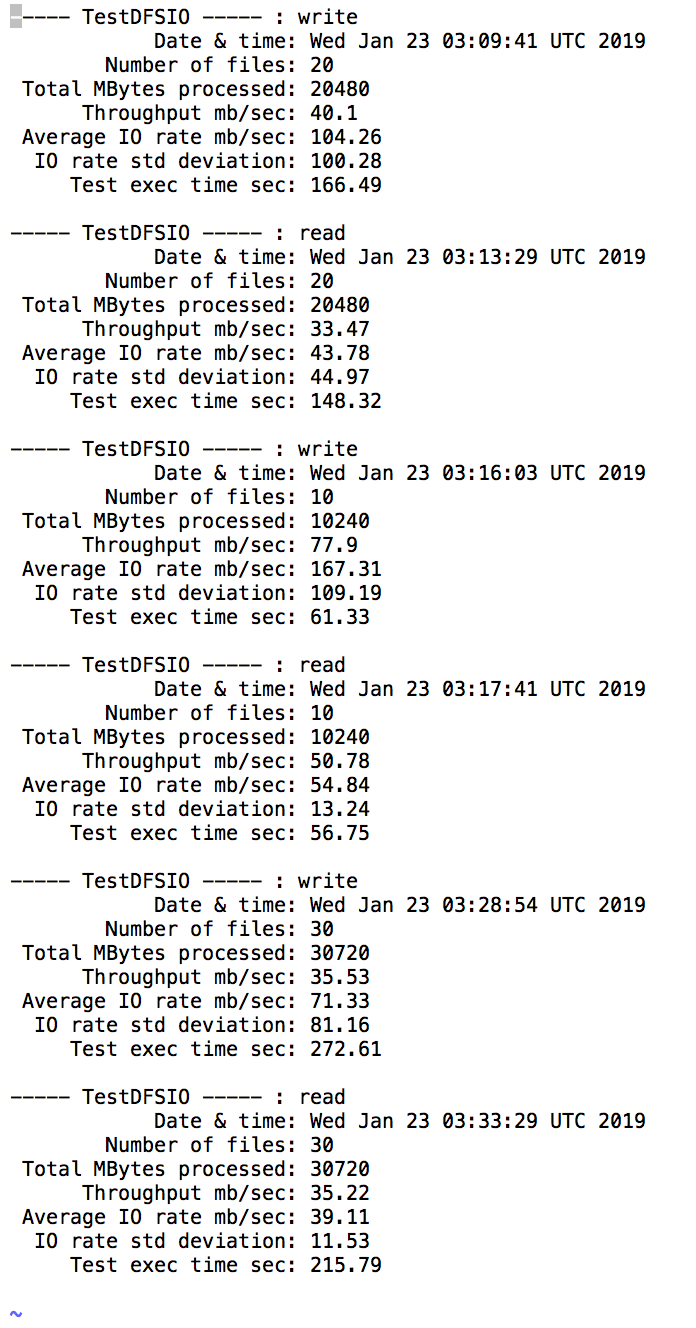
-> IO performance 보는 걸로는 쓸만 할 것 같다.
직접 만든 데이터/코드로 sort 해보기
랜덤 데이터 만들기
임의의 숫자와 알파벳으로 이루어진 10자리 문자열
import random
import string
a=0
with open('unsorted', 'w') as new:
for i in range(100000000):
digits=str(a)+"\t"+"".join([random.choice(string.digits+string.letters) for i in xrange(10)])
new.write(digits+"\n")
a=a+1
-> 파이썬 랜덤모듈 써서 만든 데이터 진짜 랜덤이라고 할 수 있을까??
데이터 분배하고 실행하기
docker cp unsorted mongodb:/home/
docker cp unsorted master:/home/
docker exec -ti mongodb bash
# sort db에 unsorted라는 collection으로 추가
mongoimport -d sort -c unsorted --type tsv --file /home/unsorted -f _id,value --numInsertionWorkers 8
exit
docker exec -ti master bash
hdfs dfs -put /home/unsorted /
from hdfs
Sort.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Sort {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "SortByCountValue");
job.setNumReduceTasks(1);
job.setJarByClass(Sort.class);
job.setMapperClass(SortByValueMap.class);
job.setReducerClass(SortByValueReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class SortByValueMap extends Mapper<Text, Text, Text, Text> {
private Text word = new Text();
public void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
context.write(new Text(value), key);
}
}
public static class SortByValueReduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable <Text> values, Context context)
throws IOException, InterruptedException {
for (Text value: values) {
context.write(value, key);
}
}
}
}
실행
#!/bin/bash
if [ -f ./Sort.jar ]; then
rm Sort.jar
fi
if [ -d "./sort" ]; then
rm -rf sort
fi
mkdir sort
hdfs dfs -rm -r /sorted
javac -classpath $HADOOP_CLASSPATH -d sort Sort.java
jar -cvf Sort.jar -C sort/ .
hadoop jar Sort.jar Sort /unsorted /sorted
from mongo
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.bson.BSONObject;
import org.bson.BasicBSONObject;
import org.bson.types.ObjectId;
import com.mongodb.hadoop.MongoInputFormat;
import com.mongodb.hadoop.MongoOutputFormat;
import com.mongodb.hadoop.io.BSONWritable;
import com.mongodb.hadoop.util.MongoConfigUtil;
public class Sort {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
MongoConfigUtil.setInputURI(conf, "mongodb://" + args[0]);
MongoConfigUtil.setOutputURI(conf, "mongodb://" + args[1]);
Job job = Job.getInstance(conf, "SortByValue");
job.setNumReduceTasks(1);
job.setJarByClass(Sort.class);
job.setMapperClass(Map.class);
//job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(MongoInputFormat.class);
job.setOutputFormatClass(MongoOutputFormat.class);
job.waitForCompletion(true);
}
public static class Map extends Mapper<Integer, BSONObject, Text, Text> {
Text id = new Text();
private Text frequency = new Text();
private final static IntWritable one = new IntWritable(1);
public void map(Integer key, BSONObject value, Context context) throws IOException, InterruptedException {
//String w = value.get("_id").toString();
String w = key.toString();
String freq = String.valueOf(value.get("value"));
id.set(w);
frequency.set(freq);
context.write(frequency, id);
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for( Text value : values) {
context.write(value, key);
}
}
}
}
실행
#!/bin/bash
if [ -f ./Sort.jar ]; then
rm Sort.jar
fi
if [ -d "./sort" ]; then
rm -rf sort
fi
mkdir sort
javac -classpath $HADOOP_CLASSPATH -d sort Sort.java
jar -cvf Sort.jar -C sort/ .
hadoop jar Sort.jar Sort 172.20.0.1/sort.unsorted 172.20.0.1/sort.sorted
Datanode 떨어졌었는데 해결법
# 내리기
docker exec -ti master bash
stop-all.sh
exit
# worker container 접속해서 데이터노드로 지정해 놓은 폴더 지우기
docker exec -it slave1 bash
rm -rf /usr/local/hadoop/dfs/data/
exit
docker exec -it slave2 bash
rm -rf /usr/local/hadoop/dfs/data/
exit
# 올리기
docker exec -ti master bash
hadoop namenode -format
start-all.sh
# jps 명령어 이용해서 확인하기
작업 listing/kill
# version >=2.3.0
yarn application -list
yarn application -kill $ApplicationId
# version <2.3.0
hadoop job -list
hadoop job -kill $jobId