Bigdata Project
구글 dataproc instance에서 진행
아마존 리뷰데이터
http://jmcauley.ucsd.edu/data/amazon/links.html
$ wget http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Video_Games_5.json.gz
$ gunzip -k reviews_Video_Games_5.json.gz
$ docker cp reviews_Video_Games_5.json {MONGODB_CONTAINER_NAME}:/tmp/
$ docker exec -it {MONGODB_CONTAINER_NAME} bash
# mongoimport --db amazon --collection video --file ./tmp/reviews_Video_Games_5.json
Spark
> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
> val video = sqlContext.read.json("hdfs:///tmp/ama/reviews_Video_Games_5.json")
> video.select("reviewerID").take(5)
> video.select("helpful").take(5)
spark로 하려했는데 wrappedarray 찾아보다가 일단 보류
hadoop으로 진행
Hadoop
코드
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.bson.BSONObject;
import org.bson.BasicBSONObject;
import org.bson.types.ObjectId;
import org.apache.hadoop.io.IntWritable;
import com.mongodb.hadoop.MongoInputFormat;
import com.mongodb.hadoop.MongoOutputFormat;
import com.mongodb.hadoop.io.BSONWritable;
import com.mongodb.hadoop.util.MongoConfigUtil;
public class rvRank {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
MongoConfigUtil.setInputURI(conf, "mongodb://" + args[0]);
MongoConfigUtil.setOutputURI(conf, "mongodb://" + args[1]);
Job job = Job.getInstance(conf, "reviewerAggregator");
job.setJarByClass(rvRank.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(MongoInputFormat.class);
job.setOutputFormatClass(MongoOutputFormat.class);
job.waitForCompletion(true);
}
public static class Map extends Mapper<ObjectId, BSONObject, Text, IntWritable> {
private final Text idOutput = new Text();
private final IntWritable scoreOutput = new IntWritable();
public void map(ObjectId key, BSONObject value, Context context) throws IOException, InterruptedException {
String id = value.get("reviewerID").toString();
String help = value.get("helpful").toString();
String [] dividedScore = help.substring(1, help.length()-1).split(", ");
int calculatedScore = Integer.parseInt(dividedScore[0])*2-Integer.parseInt(dividedScore[1]);
idOutput.set(id);
scoreOutput.set(calculatedScore);
context.write(idOutput, scoreOutput);
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
context.write(key, new IntWritable(sum));
}
}
}
실행
$ mkdir user_rank
$ javac -classpath $HADOOP_CLASSPATH -d user_rank rvRank.java
$ jar -cvf rvRank.jar -C user_rank/ .
$ hadoop jar rvRank.jar rvRank 10.146.0.2(internal ip address)/amazon.videos 10.146.0.2/amazon.video_user_rank
결과
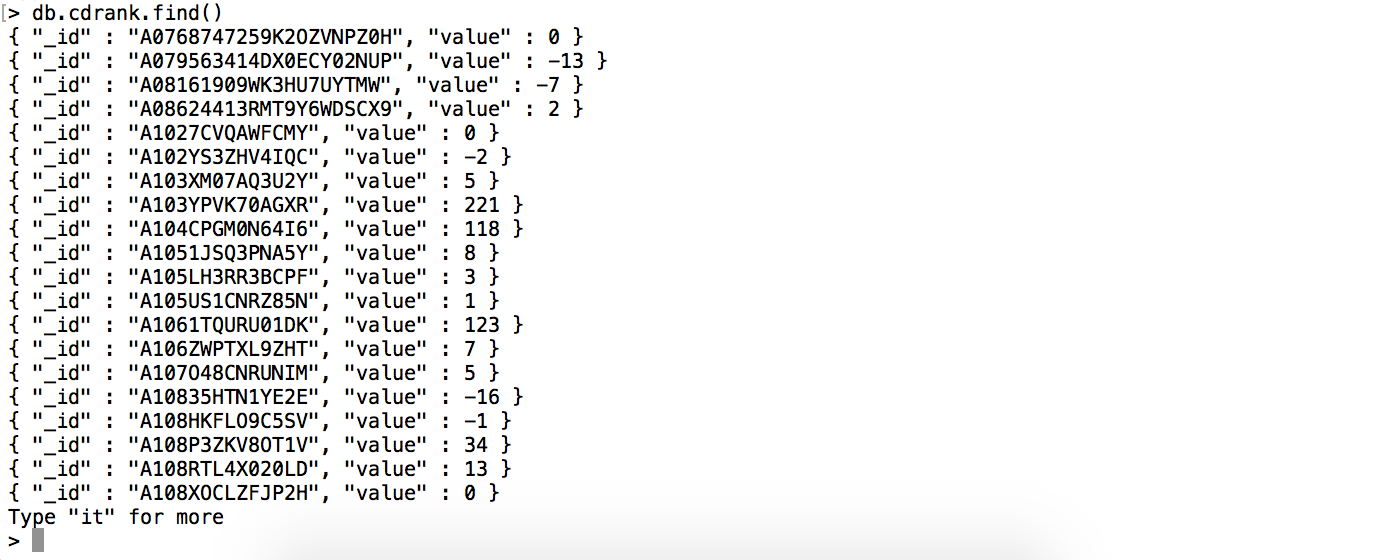
join시키기 (value column을 원래 리뷰 데이터 collection에 추가하여 새로운 collection “cd_merged” 만들기)
> db.cds.aggregate([ { $lookup: { from: "cdrank", localField: "reviewerID", foreignField: "_id", as: "fromItems" } }, { $replaceRoot: { newRoot: { $mergeObjects: [ { $arrayElemAt: [ "$fromItems", 0 ] }, "$$ROOT" ] } } }, { $project: { fromItems: 0} }, { $out: "cd_merged" ])
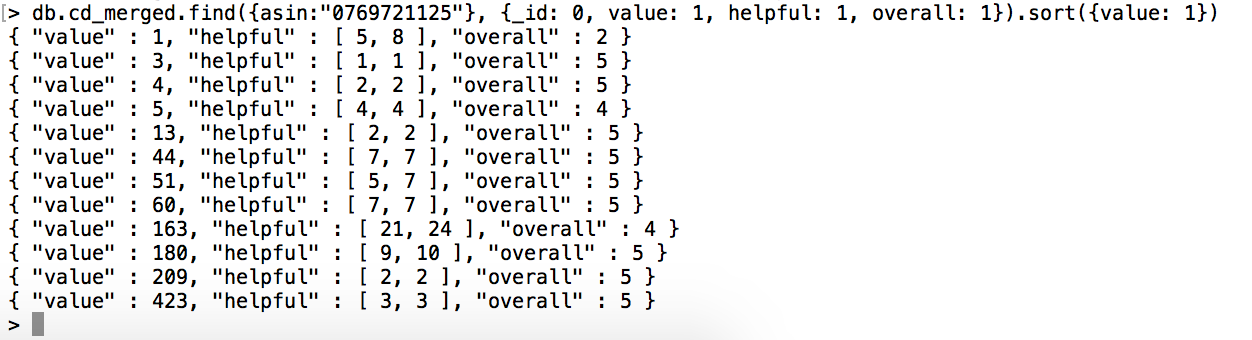
특정 아이템에 대해(asin)
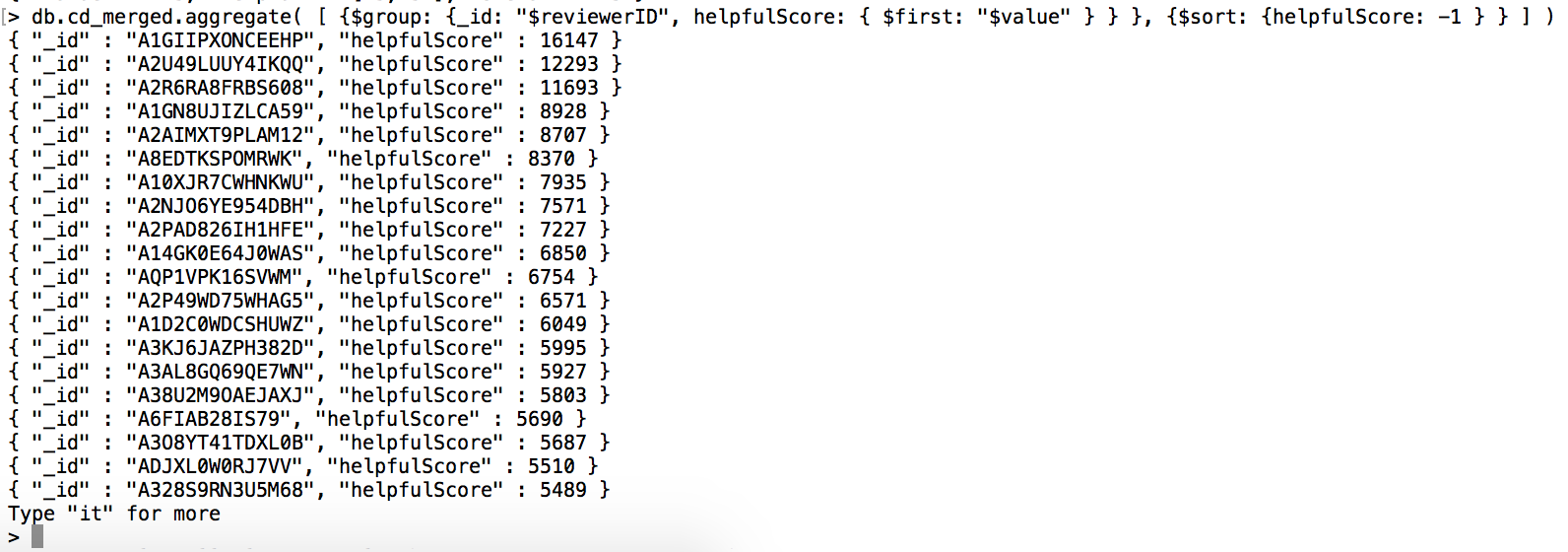
전체 유저 helpfulScore 랭킹
아마존 리뷰 데이터로부터 만들만한 다른거 없는지 생각해보기.